The back-to-back cloud outages in October 2025 exposed a deeper structural weakness across modern IT environments.
When AWS suffered a widespread disruption on October 20 — followed nine days later by a major Azure outage — organizations weren’t just struggling to restore access. They were struggling to understand what was actually impacted.
On 18 November 2025, a major Cloudflare outage caused significant failures across its global network, preventing core traffic from being delivered and showing users widespread connectivity errors.
The Guardian noted that the AWS incident showed how dependent the internet has become on a small group of cloud and infrastructure providers. DNS and authentication failures rippled across regions, interrupting authentication flows, third-party SaaS tools, and enterprise systems that quietly relied on the same infrastructure.
These outages revealed the same truth everywhere: resilience depends not on cloud providers, but on what organizations can see, manage, and control internally.
The Broader Challenge: Fragmented Oversight
Both outages revealed how little visibility organizations had into their true cloud dependencies. Many teams realized only after systems went offline that critical applications, SaaS tools, and identity services were tied to the same underlying routes and cloud regions.
As The Guardian reported, experts warned of the “perils of relying on a small number of companies for operating the global internet after a glitch at Amazon’s cloud computing service brought down apps and websites around the world.”
WebProNews captured one practical consequence: a major learning platform hosted on AWS “became inaccessible for hours, leaving students scrambling to adapt.”
Common challenges included:
- Limited understanding of which workloads were hosted in AWS, Azure, or on-premises.
- Unclear dependencies between SaaS, identity providers, authentication systems, and infrastructure.
- Difficulty identifying which departments, users, or workflows were affected.
- No unified framework for prioritizing recovery or communicating business impact.
- Overreliance on a few cloud regions without adequate redundancy or failover planning.
Together, these issues point to a single underlying problem: fragmented oversight. Organizations cannot manage what they cannot see.
Why This Keeps Happening: The Visibility Problem
Technology evolves faster than governance can keep up. As cloud adoption grows, SaaS usage expands, endpoints multiply, and tools overlap, visibility erodes, and organizations lose track of what depends on what.
During the October outages, organizations didn’t just struggle to restore access. They struggled to answer fundamental questions:
- What’s broken?
- Who is affected?
- Which services depend on the impacted region?
- What do we need to fail over — and in what order?
The real operational risk
When teams don’t know their exposure, outages escalate quickly:
- Longer downtime because teams cannot prioritize without clarity
- Identity failures when authentication flows rely on AWS or Azure
- Cascading disruption as SaaS apps fail due to upstream dependencies
- Incorrect failover sequencing due to missing dependency maps
- Slow executive communication, delaying business response
That uncertainty is the real operational risk. Without clear visibility, teams can’t contain failures or map the dependencies behind each outage.
Insights That Drive Action
Industry analysis following the outages echoed the same trend. WebProNews reported that many IT leaders are accelerating their shift toward multi-cloud architectures to reduce dependency on a single provider. A unified ITAM platform gives leaders the visibility and governance needed to make that transition measurable and sustainable.
The New Mandate for CIOs and IT Leaders
Outages like this are not rare events. They are recurring stress tests for modern digital operations.
Three capabilities now define resilience:
1. Complete, real-time visibility
Across cloud, SaaS, endpoints, networks, and identity systems.
2. Accurate mapping of dependencies
Teams must understand the full chain from system to service to workflow to business impact.
3. Evidence-based planning and decision-making
Leadership needs clarity:
- What runs where?
- What depends on AWS or Azure?
- Which services fail first?
- What happens if a major region goes offline?
- What is the upstream and downstream impact?
Resilience depends on these answers.
How Unified IT Visibility Changes the Outcome
Organizations that recovered fastest had one thing in common: unified, continuously updated visibility across their environment.
Instead of asking:
- What is broken?
- Why can’t users authenticate?
- Is this AWS or internal?
- Which region is unstable?
They were able to say:
- These systems are impacted.
- These authentication services depend on AWS DNS.
- This is the failover sequence.
- This is the business impact and stakeholder plan.
Unified visibility transforms outages from reactive firefighting into structured resilience.
Examples of reports that accelerate recovery include:
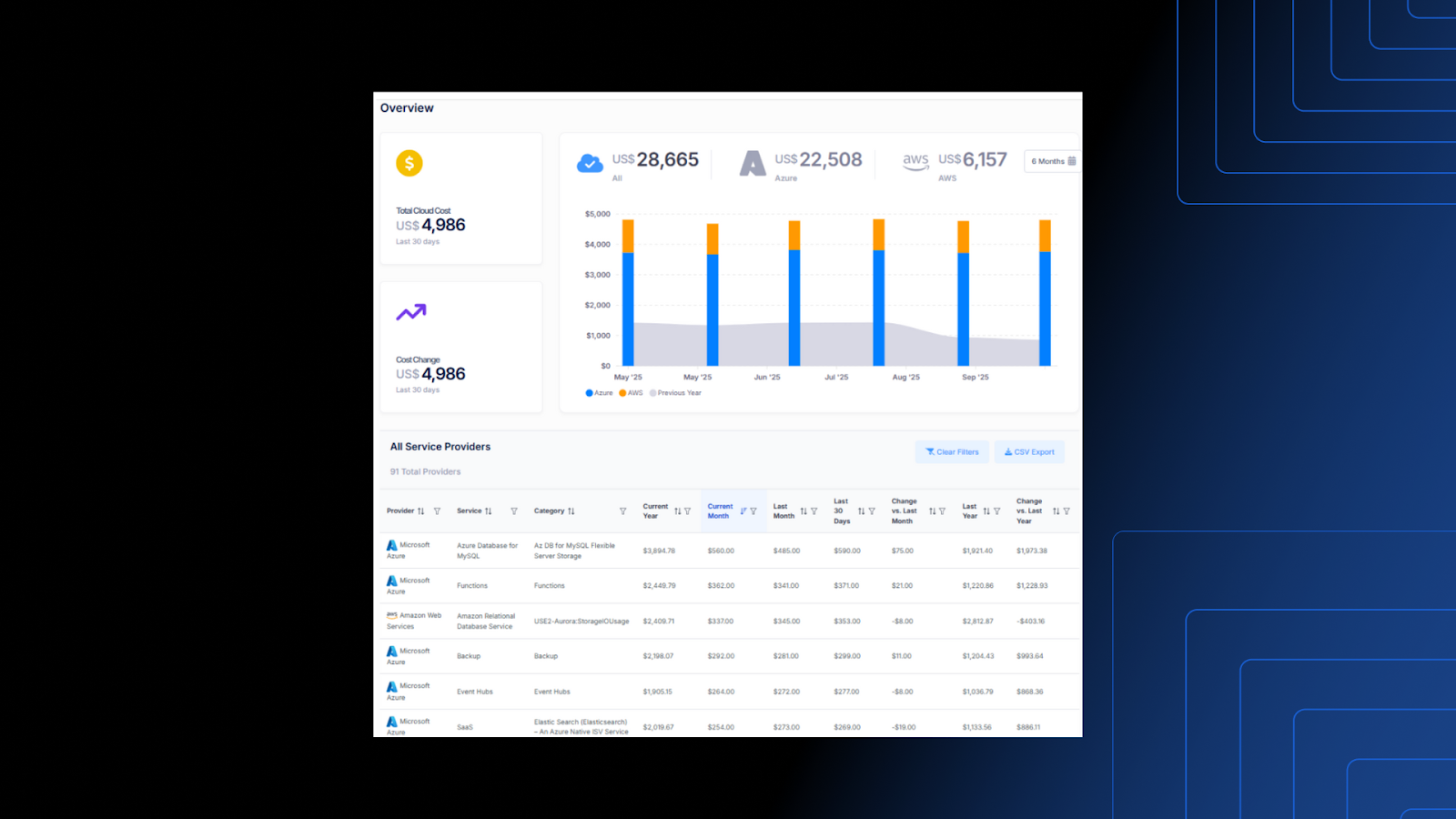
1. Public Cloud Overview Report
A consolidated view of cloud usage, spending, and dependencies — helping leaders identify where reliance is concentrated and where diversification could strengthen resilience.
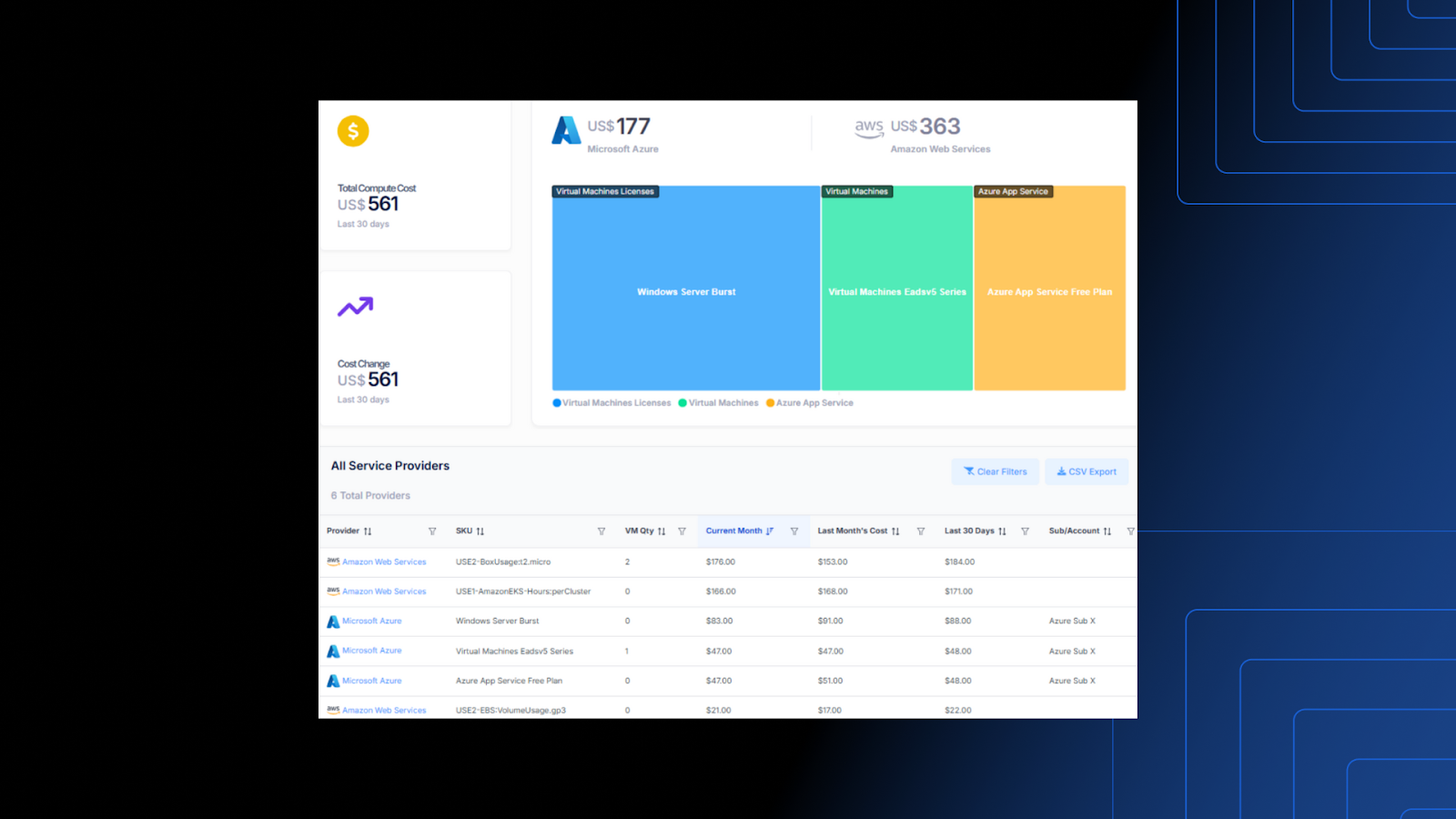
2. Public Cloud Compute Report
A mature workload inventory showing where virtual machines run, which cloud regions support
key systems, and what may be impacted during a regional service disruption.
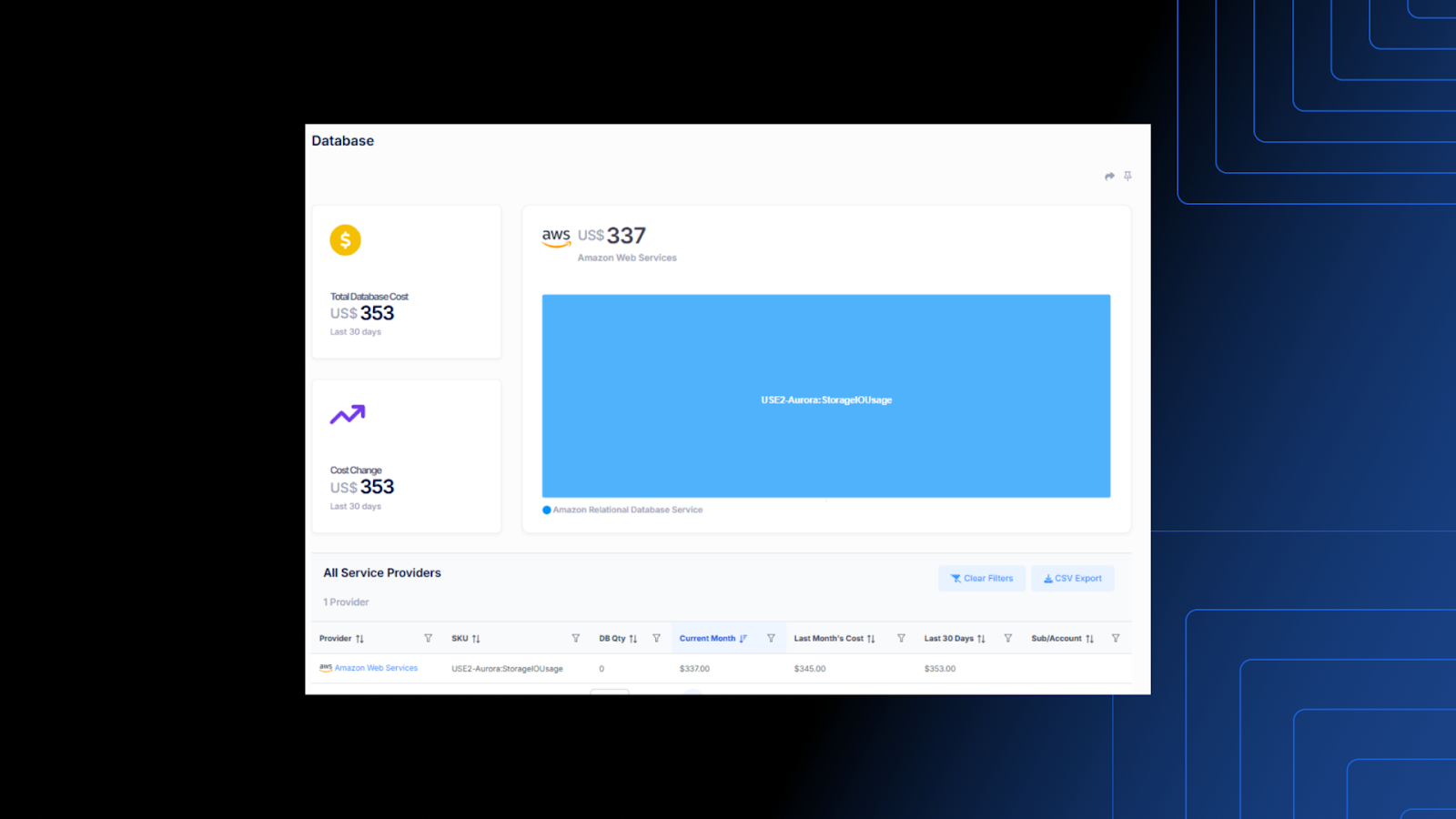
3. Public Cloud Database Report
A data-layer visibility report outlining database types, storage, cost, replication posture, and which systems depend on them — essential for continuity planning.
Together, these reports demonstrate how unified ITAM intelligence turns complexity into readiness — not during a crisis, but long before one occurs.
The Strategic Lesson: Complexity Without Visibility Is Risk
The October outages didn’t just expose cloud provider issues — they exposed internal blind spots:
- Untracked SaaS reliance
- Hidden multi-cloud architecture
- Authentication flows with undocumented dependencies
- Missing or outdated failover logic
Modern infrastructure may be complex, but resilience comes from clarity.
Organizations with accurate, unified visibility will absorb future cloud disruptions.
Those without it will scramble during every outage.
The Bottom Line
The October 2025 outages were not isolated events. They were a preview of a digital ecosystem that is powerful, interconnected, and occasionally fragile. The organizations that thrive will not be those with the most tools — but those with the clearest understanding of their environment.
Block 64 is one example of a unified IT visibility platform built for moments like these — providing a continuously updated inventory, clear dependency mapping, and real-time intelligence across cloud, SaaS, on-premises, and endpoints. It gives IT leaders the clarity required to plan with evidence, respond with confidence, and maintain continuity even when major providers falter.
Unified IT intelligence is not an efficiency project.
It is a resilience strategy.